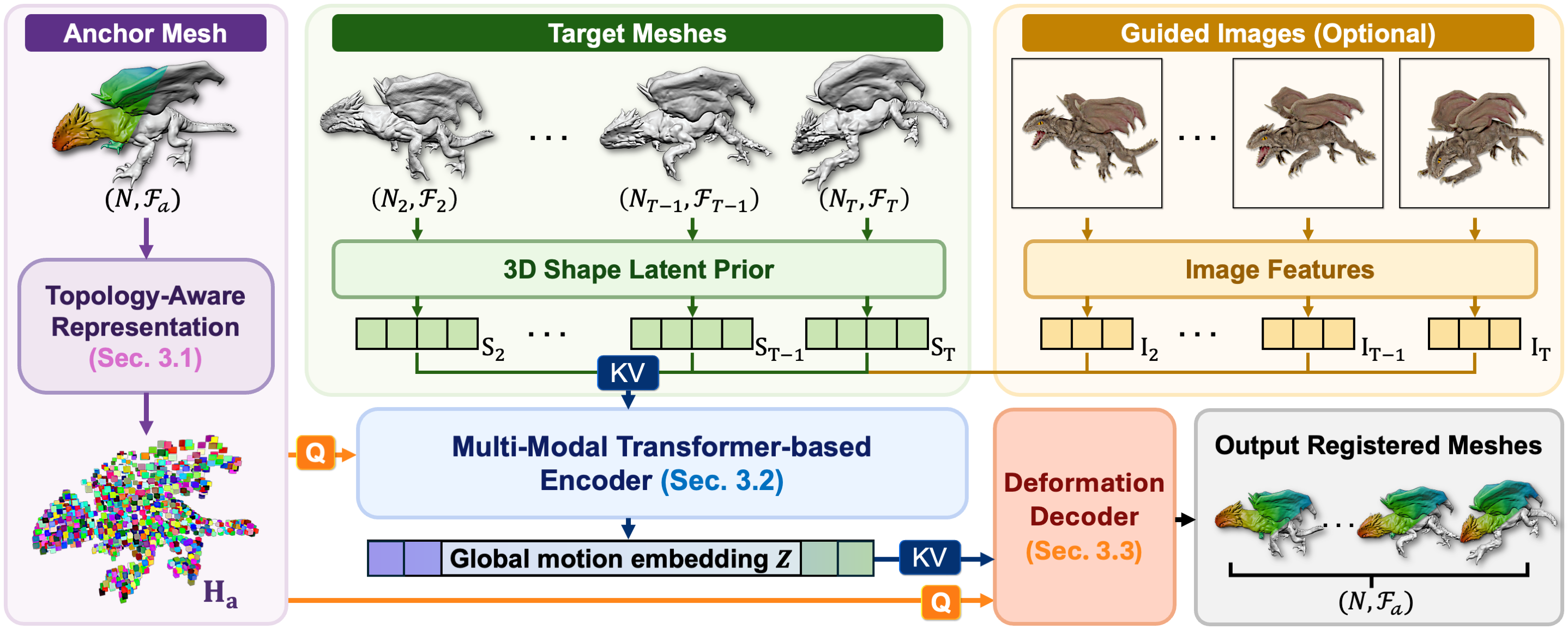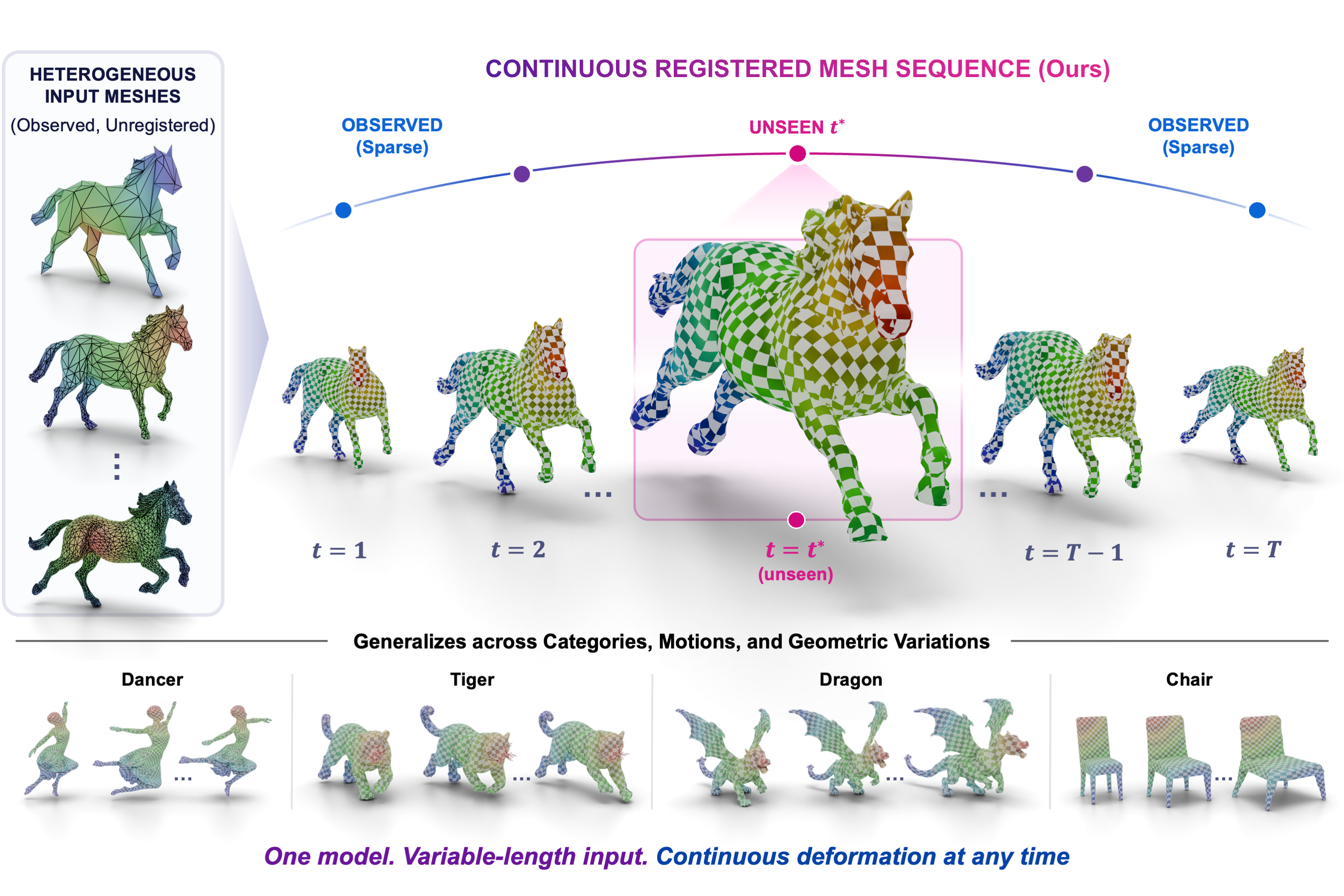
From heterogeneous inputs to a continuous registered sequence. MeshLoom takes a sparse set of observed meshes with varying vertex counts and connectivity (upper-left) and outputs a topology-consistent sequence in which every frame shares the anchor mesh's vertex set. Because the network learns a continuous motion field, it can also be queried at unseen intermediate timestamps (upper-right). The same model generalizes across categories, motions, and geometric variations (bottom). Colors encode anchor-mesh vertex positions, so corresponding vertices share a color across frames.
The Task
Non-rigid mesh registration: turn a set of meshes with different vertex counts and connectivity into a sequence that shares one consistent topology.
The Gap
Prior methods are either slow (per-instance optimization), category-restricted, pairwise-only, or output only intermediate quantities — no single method covers all axes.
Our Answer
One feed-forward network that is fast, open-vocabulary, sequence-level, and directly outputs vertex deformations — plus interpolation and morphing for free.